
2006年05月23日
Google Sitemaps
Google Sitemaps の MovableType用テンプレートがあった、今まで気づかなかったとは……
Google Sitemap
Google Sitemaps は、自サイトのURL情報一覧のようなもの(sitemap)をGoogleに送り、Googleの検索結果への反映を強化できるツールMovableType用テンプレート
Google Sitemaps using Movable Type
It's pretty easy to make an XML Sitemap of your blog for easy parsing by Google or other search engines.
2006年05月22日
「透明テキスト付きPDF」とAmazonの「なか見!検索」、Googleの「ブック検索」
参考リンク:
- [1005][PDF]PDFのバージョンについて@吉田印刷所
-PDFの歴史外観(ただし、最新フォーマットについては未出) - アマゾン「なか見!検索」って、どうよ? 2006-02-22@双風亭日乗
-2006年1月29日付の業界紙「新文化」の1面に掲載された「アマゾン『なか見!検索』についての紙上議論」という記事についての意見。書き手の詳細で丁寧な説明の仕方に好感。 - PDF 千夜一夜/PDFなんでも情報ブログ@アンテナハウス株式会社
-この会社のブログはすべて参考になる。 - さまざまなPDFの作成技術の外観>スキャナー・複合機によるPDF作成/透明テキスト付きPDF@アンテナハウス株式会社
-アマゾンの「なか見!検索」も、GoogleのBOOK検索も、「画像の上に透明テキストを重ねる形式のPDFを作ることで、透明テキストを使ってPDFを検索できる」から可能な技術なわけです。とはいえ、サーバサードでPDFを扱う技術には特別な技術が必要です。それについては、左記ページの他の項目にも目を通すと参考になります。というか、これはホントに勉強になるテキストです。
追加
- JEPAニュース 106号
書協の出版契約に関する実態調査 調査結果
http://www.jbpa.or.jp/keiyaku-jittai.pdf
感想)認識が古色蒼然……としてませんか? - 「検索エンジンは対価を支払え」:新聞団体がコンテンツ無料使用を討議@CNET JAPAN
- 「Googleブック検索」で、得をする出版社はどこなのか?@ある編集者の気になるノート
- 米Google、書籍全文の「オンラインアクセス権」販売を近く開始か? @INTERNET Watch(2006.3)-
この記事では、「インターネット書店の一種になるため、Amazon.comなどとも競合」とあるけれど、電子本フォーマットの運用管理と決済権を持つのだから、書店というよりも、読者に新型画面印刷技術を貸与する企業に近い。版元からは版を借りるだけだ(いずれ版そのものを押さえることになるのだろうけど)。21世紀のグーテンベルクになるか?
「透明テキスト付きPDF」と出版社の関係について、考えてみます。
「透明テキスト付きPDF」とは、PDFの画像化されている文章の上に、その文章が透明なテキストとして貼り込んであるPDFです。画像でもあり、テキストでもある、という二重の機能を持っています。これゆえに、本文が外部から検索可能になっています。
Amazonの「なか見!検索」も、Googleの「ブック検索」も、「画像の上に透明テキストを重ねる形式のPDFを作ることで、透明テキストを使ってPDFを検索できる」から可能な技術です。
ここで問題になるのが、著作権に関してです。著作権者の承諾を得る必要があります。もしダメな場合は、透明テキスト付きは止めて、普通の画像アルバムとしてのPDF、または、jpeg画像のみ、にしなくてはなりません。
ところでネットの上で人間が自由に行き来して立ち読みをするには、「検索」という「視点を動かす道具」がどうしても必要です。ネットのなかの人間は、脚を持っていません、それに代わるのが「検索」(ナビゲーション)になります。書物のメタ情報(著者や出版社などの情報)はすでに公開されていますが、本そのものが「開く状態」になっていてこその「立ち読み」ですから、「透明テキスト付きPDF」は、本の紹介の方法としては、現在のところ、ベターなフォーマットだと思います。
もちろん、PDFがベストだとは言えません、リーダーのワンクッションがあり、扱いにくい面も存在します。
ただ、既存の出版社のコンテンツの権利が重要になってくるなかで、GoogleやAmazonが、この方式を採用しているのは、そこに彼らが、ビジネスチャンスの「突破口」を発見していからです。それは同時に、既存の出版社にとっても、隠されたビジネスチャンスだといえるでしょう。
「透明テキスト付きPDF」の登場とその利用は、今後、特にオフィス内の文書管理において、社内サーバベースでの標準フォーマットとなり、また、インターネットにおいても、サーバによってファイル形式が自動的に変換されて利用されるなど、シームレスな利用が可能になってくると思います。
紙の出版社にとって、この流れにどう乗るかは、重要な局面です。AmazonやGoogleといった巨大企業は、流通販売の面で、脅威であると同時に、強力なパートナーになるでしょう。単純にAmazonやGoogleを否定してしまうと、ビジネスチャンスを逃してしまうことになりかねません。
書籍のメタ情報だけでなく、本文テキストの情報をAmazonやGoogle経由で流出させることで、より、本が売れるようになることもあるでしょう。
AmazonやGoogleを利用しつつ協調できる面は、
- AmazonやGoogleという販売機能を使うことによって、初版でもなかなか動かない本の、その中身を公開することによって、より多くの人に認知してもらい、本が売れるようになる(ロングテイル戦略)
- 中小書店が廃業していくなかで、Amazonはそれに代わる強力な書店である。その書店は、アフィリエイト個人書店との集合体であり、書籍と資本の動きについて、Amazonが詳細に統御している(ただし、新刊本と並列で表示される古本の販売のほうが利益率が高いはずで、出版社にとっては悩みの種)
本が売れることにより、読者、著者、出版社、流通者のすべてに恩恵があれば、よいことだと思います。
ただし、AmazonやGoogleは、多国籍の巨大企業であり、資本の論理で動く企業です。よって、日本独自の流通状況が彼らにとってマイナスだと思えば、破壊するでしょう。リアルな書店はいらない、と思えば、それを淘汰・駆逐するでしょう。
彼らが脅威となる点については、以下の通りです(少し穿った見方ですが)。
- アマゾンやグーグルの最終的な目標は、「世界中のコンテンツの出版権の奪取」だと思われる。川上においては、出版社機能を、川中においては、日本の書籍取次や書店の流通販売業務を乗っ取るつもりでいるらしい。既存の大手取次資本は、日本の大出版社と連携している、ゆえに、取次が潰れれば、大出版社も潰れる。資本関係が近すぎる。だから、警戒する
- 既存流通がなくなれば、書店の多くは廃業、超巨大ブック倉庫からの宅配便等の個別出庫・配送となる
- 流通販売に関する強力な発言権を保持することになるアマゾンやグーグルは、出版社の倉庫に対して、土日に関係なく出庫を強要する。それに従わない場合は、ウェブでの扱いに差を付けるなど、ドラスティックに鉈で既存の流通を「断裁」していく。最終的に取次事業を開始、正味の改訂等、強気に出てくるに違いない
- 書誌情報の掲載については、広告料金モデルに変更するかもしれない
- ウェブだけが本の流通・販売の窓口になった場合、検閲が簡単に行えるようになる。ある者や団体にとって都合の悪い情報は、ネット上にて、一括カットが可能になるので、資本や力を持つ者はアマゾンやグーグルの「中の人」に近づくだろう。それでさらに、力を増していく。グーグルについては、すでに、中国国内に対して情報検閲を行っている。このようにして、言論の自由が封殺される恐れが強いことは現実になっている
- PDF化された電子本が一つあれば、コピーはいくらでも可能であり、紙の本の出版、紙の本の複製販売を行う、中間媒体としての出版社は不要になる。その場合は、最初からPDFを作っておいて、ダウンロード課金する方式となり、その権限をアマゾンやグーグルが握るだろう(出版権)。これへの対抗策が必要
- グーグルにおいては、今回の日本国内のブック検索の登録において、海外での出版権について言及し、その許諾についての登録情報を設けている(明示的ではない点んい注意)。どういうことかというと、ネットにおいては国境はないのであって、海外の出版権に関して黙示的に取得する動きがあるのではないか、ということ。電子本の海外からの逆輸入販売の可能性も視野に入れているのではないか?
- 著者を育てること(半著作権取得)と、読者を育てること(購読権?)によって、出版・流通・販売のすべての流れからビジネスを行うことも可能
本に関する流通の自由、出版の自由、言論の自由を保持するため、一部の出版社は、アマゾンやグーグルに対して、一定の距離をとるでしょう。アマゾンやグーグルによる販売で、完全に依存するのは危険であり、読者に対して、複数の販売のチャンネルを開いておく必要があります。既存の書店流通を維持して、複数の販売チャンネル、読者にアプローチできる複数の仕組み(直売含めて)を維持しておくことが重要かと思います。
「紙と電子、メディアを問わない出版社」として、AmazonやGoogleなどと共存しつつ、取り込まれないように自主独立でやっていくために、今後も、ネットでの販売の仕組みや「透明テキスト付きPDF」についての扱いについて、考えていく必要があるかと思います。
(続く、かもしれない。特に、技術面について)
2006年05月20日
XHTML 文法チェッカーで校正
<追記:06/05/21 3:33 AM>
GONT-PRESS、XHTML1.0 Transitionalとしては記述にミスが多く、問題が多かった。トップのindex.htmlだけでも訂正しておくことにする。エラーのためにIEからは別窓表示で警告され、自サイトのアクセスログもきちんととれていなかったらしい。ひどかったなぁ、反省。
Another HTML-lint gateway
HTML文書の文法をチェックし、採点します
まずはAnother HTML-lintでチェック。すると、ひどい間違いの嵐が。あ”ー、ひどい認識だ>オレ。直せ直せ、学べ学べ。何度かやって、89点、スラッシュドットのニュースを読み込んで表示しなければ90点台に。
ところが、IE6で表示してみると、紙で言うところの右の煙突、float:rightが見事に下に落ちている。えぇ……? なじょして?
ネットで検索してみると、これはIEのバグのようだ。
<?xml version="1.0" encoding="***"?>と、1行目でXML宣言するとダメなのだ、<!DOCTYPE>以前に行が入ると(後方)互換モードと解釈されて、CSSがおかしくなるのだった! そりゃないぜ。。。
XML宣言を1行目に書かなければ、レイアウト崩れは防げる。……どうするか。多くの人が使っているIEを無視するわけにはいかないし、ここは宣言をはずすことにする。それでも、Win98-IE6だと右のフローティングが落ちる。ぐはぁ、面倒だなぁ。。IE7になればなおるんだろうか……。
#XML宣言をしないのは、武士が刀を捨てるような感じがする
#なんとなく、政治的な交渉で譲歩するような嫌な気分がするのだった
じつは、XML宣言をはずさなくてもよい、IE6用後方互換モード対策がありまして、それを行えば可能なんですが(下記リンク参照)、このサイトではそこまでやり抜くだけの時間がなくて残念。
#だって、月曜納品のDTP作業がまだ残っている、
#ウェブサイトのボタンアイコンだって作らなければならないし、
#ログの取得と解析・送付のCGIを書き直す必要だってあるんだよぉお。
言い訳をしている時間があればコーディングしろ、という気もするけれど、実際にやり込んでいって、そしてギリギリのところで闘えるか、どんな仕事でもそうだけど、妥協せずにどこまで深く追えるかが重要だと思う。
今日の闘いはここまでだ、次は紙の世界で闘いがある。
ともあれ、文法チェッカーで「よくできました」がもらえなくなってしまった(T_T)
□CSSとXHTMLについてじつに参考になるサイト>感謝いたします
ADP: IE6のwidth解釈バグ対処法
世界中の1%の人々へ@蒲生トシヒロ
いい加減なIE6.0の文書型宣言
アットスタイルのブログ
□XHTMLについて
Another HTML-lint>sitemap
これらのページには目を通しませう。
□文法チェッカー
Another HTML-lint gateway
「よくできました」の花マルをもらいましょう。
W3C Markup Validation Service v0.7.2
で、文法チェックしてみる。
XML宣言をすれば、This page is Validになる。合格。でも、スラッシュドットのニュースを読み込んで表示すると×になってしまうのだった。
2006年05月10日
MT、Rebuild でInternal Server Error
[追記06.05.10]
うぉい、頻発してるじゃん……(2)。冗談抜きにそろそろ対策を考えないと。MT3.2-UTF-8で全リビルドするか、引っ越すか? いや、その前に待て、と。
まずは、コメントでエラーが出るような状況を回避したい。
→コメントスパム用にフィルタ、とりあえずはずしてみた
次に、リビルド時にサーバエラー500が出る件、
→原因は何か=こちらに割り当てられたメモリが足りないから。
→解決方法は?=メモリを一気に喰わないように少しずつ使う
→ 一回の Rubild の page数 を少なくして、細切れにして作業させればいいんじゃね?
=(今のところ 40ページずつになっている)
→ どこで調整するんだろう?
→ MTはモジュールの塊だ、どこかにパラメータいじるところあったはず……
→ mt.cfg で EntriesPerRebuild 5 とする(40→5になる)
まだいじれるところがたくさんある、HACK用テクストを手にいれよう……時間あるときにあれこれ改造するのっておもしろい、つか、勉強しなくちゃ。
それに、個別ページの記述が気にいらないんだよね、使いにくいし、遷移しにくいし。「16進数カラーチャート」なんて古くて使えないから削除。もっと使いやすいように、わかりやすいようにしなくちゃ。仕事用のページも直したい。やることは山ほどあるのだった……
やりたいと思うことが山ほどあるのは楽しいことだ!
[2006-03-01 17:42:16]
Perlに割り当てられたメモリと空きのディスクスペースの問題だな。。
一度、メモリについては、ホスティング屋さんに頼み込んで
設定をいじってもらったんだが……
共有サーバだし、もともとCMS用ではなかったから、仕方ないかもね。
古いエントリを削除するのが今のところ無難な対応かもしれないけれど、
Version 2.66を消去して、UTF-8なMT3にするか
(既存のエントリは文字コードの問題があって、「再構築」となると面倒な作業が必要だけど、それも一括して、CGIを書いて自動的にやらせる、ということもできないこともないか)
2006年04月27日
favicon.icoを付ける
某サイトに設置したので、メモとして。詳しくは、Favicon Japan!!。このサイトでは、自動的にアイコン画像も作ってくれる。
ブラウザのリロード時にアイコン画像のキャッシュがクリアにならないことが多くて、なかなかアイコンが表示されず、どうしたものかと思ったけど、一度終了させてから再び開くと、表示できた。
アニメーションgifやpngまで作ってくれるアイコン画像作成サイトは、FavIcon from Pics -- favicon.ico for your website。
アイコン画像として、pngファイルも設置できる。この場合は、
<link rel="icon" href="http://****/favicon.png" type="image/png" /> と書く。
(参考:favicon (ショートカットアイコン) のまとめ)
RSSフィードでは、index.rdf で、
<image:favicon image:size="small"
rdf:about="http://www.*****/favicon.ico">
<dc:title>******ICON</dc:title>
</image:favicon>
と記述する。
なお、朝方までまたしても作業しているのには理由がある。共同で作業をしている作業者に「アイコン付けようと思うのだけど、どうでしょ」と相談した時に、「その作業ってクライアントからの指示? 指示があったならメールをフォワードして」と聞いてきたので、はぁ? 君はさー、指示されなきゃやらないの? サイトがよりよくなるように自主的に作業しようというこちらの考えには賛同できないわけか……わかった、君には頼まない、オレが自主的に自分の責任でやるからいい、と。人によって考え方違うから、それはそれでいいんですけどね。
2006年04月24日
XMLRPC::Liteを使う(更新サーバにpingを打って更新を知らせる)
先月、某サイトのお仕事で作ったのはCGIのRSS機能だった。サイトのデータベースで更新があったときにindex.rdfを出力させてみた。でも、それだけじゃRSSとしての意味が薄い。更新サーバに「更新しました」というお知らせ(ping)を打たなきゃ。
RSSを出せるようになったら、今度はそれを飛ばす=告知する=出版する(publishする)。
で、普通のサイトでも、WEB2.0風味で使えるように、手動でpingを打つCGIを書いた。どうやら反映されているようだ……02時半か……寝よう……サーバでLite.pm(XMLRPC::Lite)が使えたら、CGIを作って動作させるのは、それほど難しくはないです。
参考にさせていただいたのは、
古くからお世話になっているCGI RESCUEさんの「ブログ・ブロキュー(bloq) 改造」
XMLRPC::Liteモジュール (SOAP::Lite v.0.50)(日本語チョー訳)
by Hippo2000(2001/5/23)
Excite エキサイト: ブログ>ヘルプ>PING送信について
▼Bulkfeeds
PING送信URL:http://bulkfeeds.net/rpc
▼Myblog JAPAN
PING送信URL:http://ping.myblog.jp
▼PING.BLOGGERS.JP PING送信URL:http://ping.bloggers.jp/rpc/
▼Technorati JAPAN
PING送信URL:http://rpc.technorati.jp/rpc/ping
▼WEBLOGS.COM
PING送信URL:http://rpc.weblogs.com/rpc2
▼blogoon
PING送信URL:http://ping.blogoon.net/
▼ココログ
PING送信URL:http://ping.cocolog-nifty.com/xmlrpc
▼gooブログ
PING送信URL:http://blog.goo.ne.jp/XMLRPC
25 April 2006 追加
XML-RPC§更新Pingの送信@snot.jp/wiki
2006年04月21日
気になってついRuby
いやね、このまえアキバの書泉で宣伝してたもんで、気になってついRuby。
ツッコミ可能なWeb日記システム"tDiary"の公式サイト
tDiaryの中の人ですか、Ruby。とっかかりはここだな、いつも最初は掲示板から。
CMSみたいな道具は、顧客の囲い込みに使われるばっかりだな、もっと遠巻きに離れた感じで静かに繋がってるのがいいと思うよ、広告で重くなってくばかりのCMSだったら、tDiaryのほうが楽しい、はず。
2006年02月07日 大きな文字、大きな夢
[blog]tDiary専用 高橋メソッドプラグイン「bigpresen.rb」
あはは好きだ。これ。へぇボタンとか押しちゃった。
Ruby on Rails(ルビーオンレイルズ:RoR)とは?
いつか、たぶん。
2006年04月12日
JavaScriptで本の立ち読み機能

■ブラウザ立ち読み機能[PaIm](β版)
[主な機能]
・画像の拡大/縮小
・画像の順送り、戻し
・画像の自動送り/停止
*書籍の見開きページ画像の閲覧用に制作
*JavaScriptで全制御。ソースはどうぞご覧ください
*JavaScriptの雛形はネットで見られる既存のプログラムを参考にさせていただきました。
制作者たちに感謝。
*CGIを利用して画像を自動的に読み込む[PaIm]実装版は上記画像をクリック
2006年03月26日
鎖国を止めて開国する
黒目川沿いはとっても春、お花がきれい、メカニカルの一眼レフで撮りたい、冷蔵庫に閉まってあるポジフィルム使いたい、使い始めたら最後まで使い切りたい、だから、黒目川花シリーズというテーマでの撮影はとてもよい企画だ! と思ってるのだけど、なんせ時間がない、うぅ、仕事終わらないっす。これは地元U氏にお願いするしかなかろう……そういや、デジカメで28mmでましたね。
さて、外に出られないなら、内側から扉を開けよう! ということで、突如、開国宣言してみた。
開国っても、このサイトの話ですよ。コメント・トラックバックスパムで嫌になって、deny from all,allow from jp なんてディレクトリごと鎖国してたわけですが、各種ロボットさんやpingサーバさんから「ゴルァ、ガンガン、開けろぉ(AA略」と最近うるさくなってきたので、スパム対策をして、開国に踏み切ることにした。春ってこともあるし、窓開けて、ゴミブログを投げ捨ててまき散らすのも桜花吹雪でよいかな、と。とはいえ、辺境で伊集院光がぐるぐると回している極彩色の風車に突撃していくような人がやってるサイトなので、開国したって黒船一隻やってきませんし、この島にはそもそも黄金はありません。ほんとは、みなさんに役立つ何かを提供する、それが重要だとわかっているんですけどね……
黄金じゃないけど、ひとつ、作ってるものがあります。出版社のサイトに役立つ仕組みです。5月連休あけたら、公開できるかもしれません。
2006年03月25日
単純な画像アップローダー制作
blogとは直接関係ないけれど、画像アップローダーを書く。うーん、すごく単純な道具なのに時間かかりすぎ。禿げしく眠い。
いずれ公開するかもしれないが、今はその時間がとれない。また後で。
#【画像アップローダー***.cgi[ガップン]】
#Ver1.0 by GontDo on 03/2006
#Last Modified on: 03/2006
#いろいろとネットでスクリプトを参考にさせていただきましたm(__)m
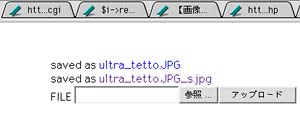
その機能は、
・.jpg画像を一個ずつ、サーバにアップロードする
・画像は、CGIのあるディレクトリと同じディレクトリにアップされる
・ファイル名は変わらない
・アップロードすると同時に、_s.jpgを付けたサムネイル画像が作られる
(この場合は、左右80pxに合わせて、天地左右等倍縮小)
(CGIの該当箇所を書き換えれば、縮小率も変更できる)
(シャープネスかけたりインターレースになったり)
・条件:Image::Magick(perlmagic)がサーバにインスコされてること
Image::Magick は、MTでも使われている画像アップロード機能を有効にするアプリなのだけど、入ってないこともある。となると、画像アップローダーが動かない……それはまずい、ということで、Image::Magickが入っていなくてもサムネイル作成が可能な方法を採用し、別のスクリプトも書く……。
##【画像アップローダー***.cgi[ガップリン]】
行き当たりばったりなネーミング、ま、似たようなもんです(^^ゞ
利用させていただいたのは、
#ImgResize.pm@cachu
#repng2jpg (菅さん作)
であります、隊長!……うー、眠い、眠すぎる……ガクッ…バタっっっZZZZ
2006年03月07日
既存の単品ウェブ注文フォームにクッキー機能を付ける
blogの仕組みとは直接関係ないんだけど、最近にわかに喧伝されている「WEBほにゃらら」に触発されて、ハックな作業をやっている。
JavascriptとCGIをかませてクッキーの書き込みと読み出しをさせる機能を付ける作業をしている。既存のカートを使えばすでに実装されているような機能なんだけど、カートを使っていないウェブメールの注文では必要な機能、あんがい付けられていないことが多い、なぜかというと、設定が面倒だから! クッキーを使わないと、何度も同じ情報を入力しなくてはならないので、利用者にとっては不便だ。利用者にとって不便なところを改善して便利にする、これが仕事だろ>オレ ここで止まらないで(^^ゞ 書き込み・読み出しの感覚を覚えていきたい。最近ではJavascript絡みでAjaxもあるわけで、学ぶことはいっぱいある。
2006年03月02日
普通のサイトにRSS配信機能を付ける
難儀したけれど、CGIで書き出せるようにしました。
仕事で担当している版元サイトのバックヤードはCGIの簡易DBになっていて、
DBに新刊を追加した時に、rdfが書き換わるようにしました。
blogなどの裏方の技術はおもしろいけれど、やればやるほど、
朝になってしまう、し、しまった……寝よう。。
2006年02月21日
JP DNSの更新間隔短縮
JP DNSの更新間隔短縮の実施について@JP 日本レジストリサービス手続き後、15分程度で利用開始可能
これからは、独自の汎用JPドメイン名でのWebページ即時開設等をラインナップに加えるサービス提供者が出てきます。それにより、「思いついたら即実行。すぐに独自ドメイン名を申請、Webを公開」ということが可能になります。
新規だけね、新規の方だけ。。
2006年02月08日
RSSベースのアンテナ
深夜、MTのRSSFeedをいじる。昨秋から改造したくて仕方なかったのだけど、先延ばしにしていた。なんでこんな夜にやっているかというと、忙しいからだ。忙しいと、ついつい、逃げたくなるのだった(^^ゞ 目途は立ってます、大丈夫です……>関係各位
テンプレなどを書き換えつつ、ウェブの更新は一発でサクサクできないとダメだなぁ、もっと便利に、いろんな情報を編集できないだろうか、なんて思ったりする。Perlで動く、RSSを取得するアンテナ・プログラムないかな、と思って探してみると、ありました。便利なものだな。。
RSSベースのアンテナ「RNA」RNA は、Webサーバ上で動作する、RSSアグリゲータの一種です。 Perl/CGI で実装されています。 Web上のいろいろなサイトの更新情報を収集するアンテナとしての機能が主ですが、FOAF技術を用いた、コミュニティ(もしくは知人)ベースの連携機能も有しています。 セマンティックウェブ 関連の技術を用いてWeb空間を再編集するというコンセプトのもとに、semblogプロジェクトにより開発されています。
ところで、アンテナが作られたのが2004年ぐらいで、技術的な「熱い丘」は昨年2005年の夏には通過したように思える。
上記のアンテナを作った中心は早稲田の理工にいる学生と研究者で、この技術をもって、会社を立ち上げているのだから。
Semantic High! グルコースの中の人のブログ
おもしろいなぁ……これを見てかなり焦った。しまった、遅れすぎだ>オレ CMSを使った新たなサイトとサイト連携(Web空間)、最近言われるWeb2.0に触らないといけない。個人的にはブログ・SNS・ソーシャルウェアの閉鎖的なトライアングルは好きではないのだけれど、閉鎖的にみえるのは、そこには資本:広告が投入された空間としての縛りがある、ということだから、仕方ないと考えるべきなのだろう。そうした小さな母集団での実験を経て、外部へ外部へと出てくる技術、そして、技術を支える思想があるはずで、それを自分なりに再構想してみたいと思う。2006年春、全力で学べ、追いつけ、技術的にも表現的にも思考的にも、新たな領域を確保しろ>オレ
2005年11月05日
コメントスパム対策-1
ひでぇ……最近、山ほど来ちょる。。削除する時間もかかるし、IP制限してもすぐに別のIPで投げられるから止められない。ええい面倒だ……外国からの閲覧をすべて拒否、んで、 .日本 だけ通すことにしよう、いわゆる鎖国。
巻き添え喰ってる方は、メールでもください。通します。全面的にコメントを不許可、でもいいんですが……さしてコメントもない辺境blogなんで、マターリ見てもらえばいいわけで(´ー`)_且~
外国スパマーの馬鹿どもが自動的に投稿してるとなると難しいが、HTMLを触ってるなら、これで効果はあるはずだ。他の方法で自動投げしてるとなるとcgiそのものを一部書き換える必要があるのかも……。
2004年05月21日
2004年05月19日
URLリンクタグメーカー
javascriptで「URLリンクタグメーカーver1.1」(.html)を作りました。
*04/05/20 11:18/IE-オペラ環境他では生成されません。フォームのアクセスの仕方を分岐する処理はまだ書いてません……後で手直しいたしますです、はい。。
ブラウザで開いておいて、コピー&ペースト、ボタンで一発。これでページ作成もラクラク……? ほんとかな? IMGタグverも作れそうですし、適当に改造しまくってお使いください。
なんで作ったか→紹介したいページのリンクタグを何度も作るのは面倒。相手先がblogだったらBookmarklet「Post to MT Weblog」で自動だし、普通のページだったら、エントリーの装飾ボタンを使えばできるけれど、結局はエディタを開いてURLやページタイトルをコピペして、タグを書くことも多い。タグ入力支援ソフト類を使っていてもやはり面倒……だから。
2004年05月18日
MTのカテゴリーの並び順を任意にする
カテゴリーを任意の順番に並べて表示する方法については、以下のサイトを参考にさせていただきました。ありがとうございます。
maruchannel: カテゴリーを自分の並べたい順番にする
MTのカテゴリ別エントリー一覧
INDEXなどに、カテゴリ別エントリーの一覧表が出ないかな、と思って、調べていって、「これだ!」というサイトを見つけて参考にさせていただきました。
noblog::短気な猫3rd
上記サイトの「カテゴリ別エントリー」の表示の仕方、スタイルシートと連動してますね。思いつかなかった。
MTのタグの使い方を間違えると、エラーが出て「なんでだろぉ!!!」と思ってましたが、以下のコメントで解決?するかもしれません。参考になりました。
Movable Typeスレッド その5@WEBプログラミング@2ch掲示板
テンプレートのMain Indexに、以下のようなタグが入ってます。うまくいくことを願います。
MTで「本日のリンク元」表示
晴ときどき鬼瓦。: MovableTypeでtDiary風「本日のリンク元」をやる。(パッケージ完成)
MTを動かしてから、どこから参照されてるのか、ちょっと気になったので、取り付けてみました。ありがとうございました>鬼瓦さん
2004年05月15日
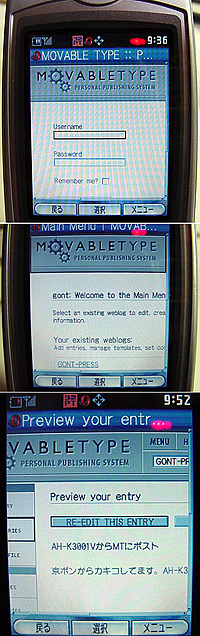
AH-K3001VからMTにポスト
京ポンからカキコしてます。AH-K3001VからMTにポスト
パソからの追記04/05/15 22:42
MTへのログイン画面
2004年05月14日
mt-rssfeed.pl、mt-jcode.pl
『ウェブログ入門』を開きつつ、MTのプラグイン、RSSパーサーの設置を試みる(自分のMTの文字コードの環境はeuc-jp)。かなり難儀してしました。テンプレ保存時のエラー、本文またはRSSファイル読み込み表示時の文字化け。この二つを解決しなくちゃいけない。
【第一関門】保存時にエラーが出てしまう
・mt-rebuild.pl をFTPでputしておくと、保存時にエラー頻発
→mt-rebuild.plは削除しておかないとダメだった
【第二関門】本文文字化けの嵐
・第一関門クリア後、表示されるようにはなったものの、ページ全体が文字化けしている
→うわぁあ。結局、いくつかのサイトを参考に、方法を拝借した。新しいテンプレートを作成し、そこにRSS取得の行を書き入れ保存、これをMain Indexのテンプレからインクルードする。
しかし、それでも文字化けする。なぜなんだろう。
で、こんなことをしてみた。
・新しいテンプレに書き込む行には、 jcode="euc"は入れない
・Main Indexのテンプレからインクルードする時に、 jcode="euc"を入れる
ex.
<$MTInclude file="hogehoge.html" jcode="euc"$>
ブラウザが読み込む時に文字化けするのだから……この方法でOKなのかもね。
参考サイトは後で一覧にいたします。すんません。
2004年05月13日
2004年05月12日
.jsファイル読み込みの文字化けを回避
最初、ココログのRSSの.jsファイルを自分のサイトに読み込んだら文字化けしてしまった。
あちらはutf-8、こちらはeuc-jpだから。それで、文字化けを防ぐにはどうしたらいいだろうと思い、ググってみた。
方法は
1.utf-8のサイトに一から作り替える →やだ
2.CGIで相手先webサーバにHTTPリクエストを送り、.jsデータを取得した後に、文字コードをeucにデコード、これをexecでhtmlに読み込む
→あれこれやってみたが、うまくいかない。まだ学習が足りない。
参考サイト:
CGIの小部屋
Unicodeデコーダ「simaguni.pl」(utf-8→eucなど)
そして、以下のサイトで方法がわかった。
「JavaScript の Include 命令を書き込み、インクルードされる .js ファイル内には document.write で HTML を出力する JavaScript コードを書き込んでおくと、ブラウザ上でそれらのコードが実行されてマージされ、レンダリングされるという仕組み」
RSS feed を JavaScript で HTML に埋め込む
Blog Developer's Cookbook
3.上記の引用のサイトに書かれていた、「charset="utf-8"」!! たったこれだけのことだった……うわぁ、なんて遠回りしちまったんだ。感謝。
そんなわけで、初歩的な部分で既にボコボコにされ、激しく膝を折ってしまった。もう今日は寝る! 次回、時間があれば、プラグインで躓いてみたい(笑)。
2004年05月11日
MacOS9でのMovable Type
Macユーザーでも、これを見ながら手作業をおこなえば対応できるでしょう。自分はMacOS9がデフォルトなので、ともあれ、感謝>Milano氏。忘れないうちに……
日本語パッチの内容公開@Milano::Monolog
ところがです、Mac環境での変更には途中で疲れ果て(笑)、結局はWin環境での作業をしてからFTPでMacに引き戻し、そこからサーバにputすることに。
その後、あぁ、EUCでやっちまったなぁ、と。いかん、UTF-8に変えようかと思って方法を探してググったりして「みんな同じ問題にブチ当たってるな」と思ったんですが、考えてみれば、自サイトでは外部のCGIのprint文を読み込んでるから、UTF-8にしちゃ面倒なことになる。
ムムム、いたしかたなし。どうせやるなら、別のサイトを作ったほうが早いということに。というわけで、このまま行きます。
2004年05月10日
ヨコ3段組にする
段組にするならテーブルだけど、すべてを読みこまないと表示しないから、テーブルを使わないでうまく表示できないかな、と。
それでテンプレートのスタイルシート(styleseet)をいじってみた。デフォのMac環境で作り、圧倒的多数のWin-IE環境で確かめつつ、何度もテンプレをいじりってはリビルドする。
3段組にすると、環境によって右の煙突組がはじかれて、コンテンツ下の左下に飛んでしまう。
結局、index.htmlの左右を800pxとして、左200px、真ん中350px、右150pxで固定するヨコ3段になった。上には左右800pxのバナー画像、下には、ssiで読み込むCGIを置く。これは、DTP仕事で担当した最近の本のデータをprint文のテーブルの中身だけ呼び出して5段で表示する仕組みになっている。
他のページはFormの左右の幅を変えないままにしたので、どうしても右の段が収まらず、2段に落ち着いた。
他の環境で確かめてみると、コンテンツそのものをセンタリングしないと右が余ってしまう。で、divタグやらcenterタグやらを使ってみるが、どうもうまい具合にいかない。とりあえず、作業はここまでにして、また試してみようと思う。
2004年05月09日
Similarity Searchを入れてみる
関連する記事を自動的に引きつけて表示する磁石みたいな仕掛け。
まったく関係ない記事が「ひっつく」のがおもしろい。シュールというか、暗黙で辛辣な批評というか……たとえば、このblogに書いた「山岳走」を開くと「珍走団」がくっついてくる(笑)。こういう偶然がニヤリと楽しい。
Bulkfeeds: Similarity Search リリース